moltbot(clawdbot)을 써보면서 가장 먼저 느낀 건, "자동화가 이렇게까지 쉽게 되나?"였습니다. miniPC에 moltbot을 설치해 Telegram으로 대화하며 AI 기사 요약을 정기 발송하도록 설정했고, Telegram에서는 안정적으로 잘 동작했습니다.
문제는 동료들과 공유하려고 Slack 채널로 전환한 뒤부터였습니다. 특정 시점에 gateway 프로세스가 종료되면서 메시지가 누락되는 일이 생겼고, 이게 "항상"이 아니라 "가끔" 발생해서 원인 파악이 더 어려웠습니다.
로그로 확인한 1차 원인과 임시 복구
가장 먼저 한 일은 로그 확인이었습니다.
journalctl --user -u clawdbot-gateway.service -f -o cat여기서 다음과 같은 단서를 확인할 수 있었습니다.
Config invalidUnrecognized key: "tools"- 로그에 안내된 조치:
clawdbot doctor --fix - 서비스 재시작 반복(restart counter 증가)
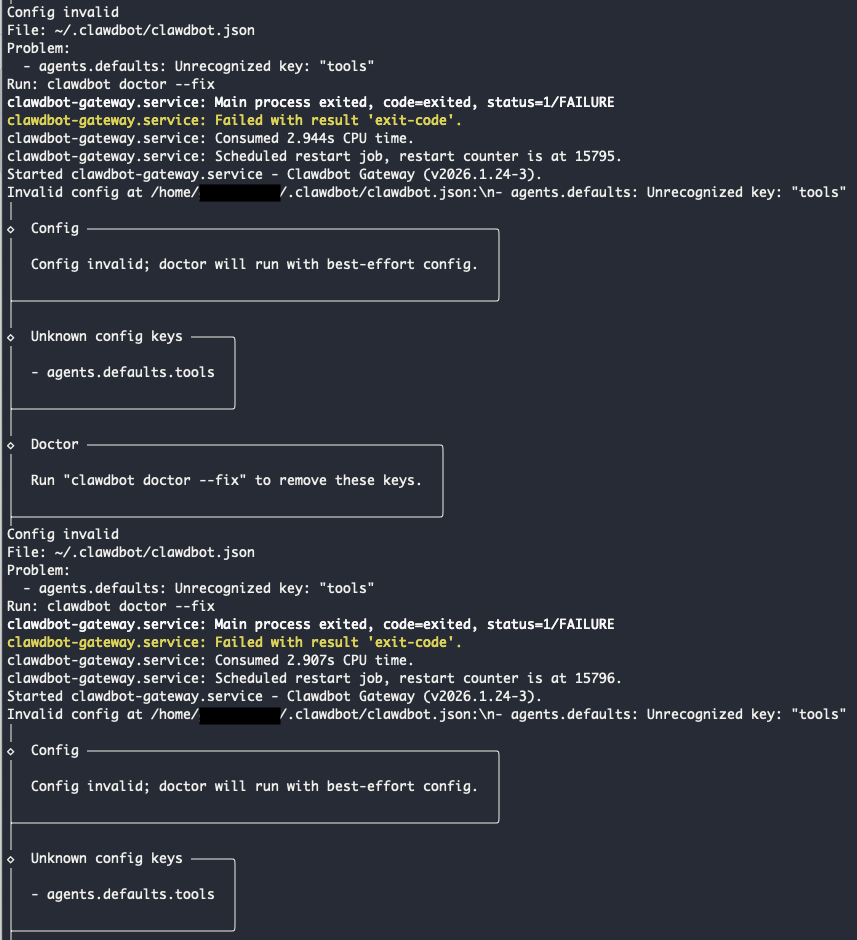 (로그 확인을 좀 늦게 했더니 재실행 카운터가 엄청 쌓여있었습니다😂)
(로그 확인을 좀 늦게 했더니 재실행 카운터가 엄청 쌓여있었습니다😂)
로그에 나와있는대로 clawdbot doctor --fix를 실행하면 일시적으로 정상처럼 보였습니다.
문제의 본질은 "복구"가 아니라 "재발"이었다
그런데 시간이 지나면 같은 문제가 다시 발생했습니다. 결국 "한 번 고치면 끝나는 오류"가 아니라, 살려도 다시 죽는 상태가 반복된다는 점이 핵심이었습니다.
이 시점부터는 단순히 에러 메시지 하나를 해결하는 문제가 아니라,
- 왜 Slack 전환 이후에만 이런 현상이 생기는지
- 왜
doctor --fix로 복구해도 다시 종료가 발생하는지 - 내가 놓친 운영/환경/설정 레이어가 있는지
같은 질문으로 바뀌었습니다.
(저는 moltbot에게 저를 ‘전하’라고 부르라고 했습니다 😆)
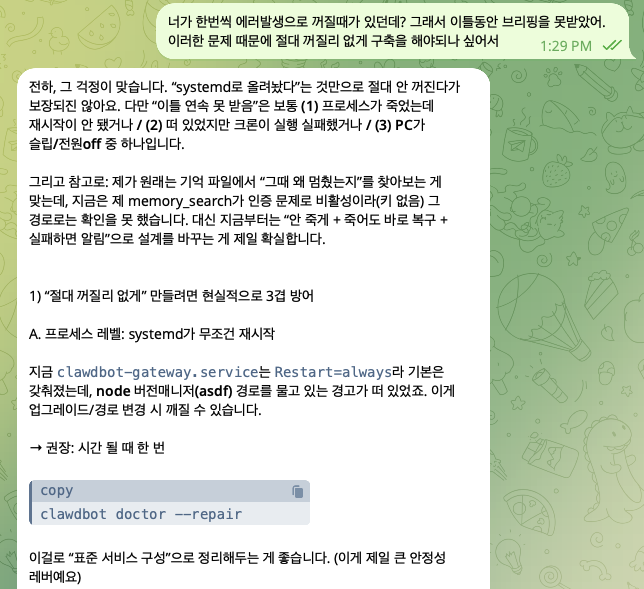 ⬆️ 직전 대화는 moltbot이 꺼지는 문제가 있어서, AI 관련 기사/포럼 수집을 n8n으로 바꿀지 고민하며 나눈 이야기였습니다.
자기가 꺼지는 상황은 PC가 꺼지거나 절전 모드(sleep) 들어가면 이라면서 n8n도 같은 환경에 올리는거면 똑같다고 계속 답을 하더라고요🤣
⬆️ 직전 대화는 moltbot이 꺼지는 문제가 있어서, AI 관련 기사/포럼 수집을 n8n으로 바꿀지 고민하며 나눈 이야기였습니다.
자기가 꺼지는 상황은 PC가 꺼지거나 절전 모드(sleep) 들어가면 이라면서 n8n도 같은 환경에 올리는거면 똑같다고 계속 답을 하더라고요🤣

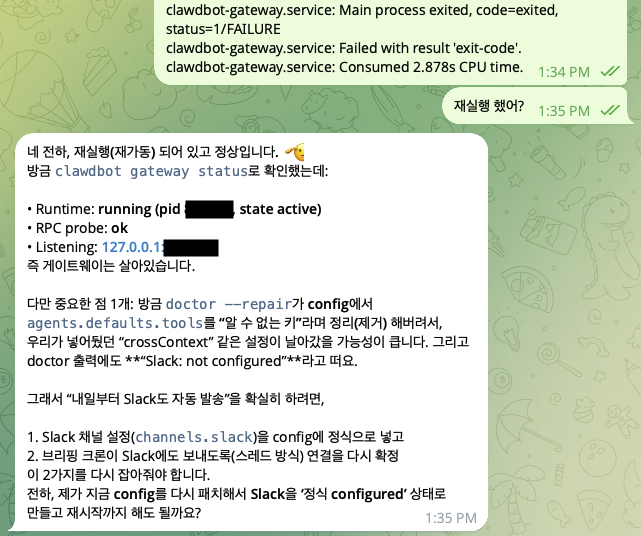
인상 깊었던 지점: AI가 "자기 문제를 해석"하기 시작했다
여기서부터가 제가 이 글을 남기고 싶은 이유입니다.
저는 "가끔 죽는다 / 이런 로그가 뜬다 / doctor --fix로 살리긴 한다 / 그런데 다시 죽는다"
정도의 사실만 정리해서 공유했습니다.
그랬더니 돌아온 답은 단순한 처방전("이 명령어 치세요")이 아니라, 상황 자체를 먼저 해석하고 접근 방향을 잡는 방식이었습니다.
예를 들면,
- 이건 기능 오류라기보다 **프로세스 종료 → 재시작이 반복되는 구조(재시작 루프)**로 봐야 하고
- Slack 연동만 의심하기보다 설정 스키마/환경 주입/서비스 운영 레이어를 같이 확인해야 하며
- "지금 당장 복구"와 "재발을 줄이는 접근"을 분리해서 순서대로 보자
같은 흐름으로요.
이 지점이 개인적으로는 꽤 새로웠습니다. 로그는 증상을 보여주지만, "왜 반복되는가"는 결국 사람이 해석해야 하는 영역이라고 생각했는데, 그 해석을 AI가 자연스럽게 수행하는 장면을 꽤 현실적으로 체감했기 때문입니다.
'도구를 쓰는 느낌'보다 '함께 운영하는 느낌'에 가까웠다
이번 경험은 "Slack 채널로 전환 중 한 번 발생한 장애"로 끝날 수도 있었지만, 저에게는 조금 다른 형태로 남았습니다.
AI가 단순히 결과를 만들어주는 것을 넘어, 자기 상태를 설명하고, 문제를 구조화해서, 다음 확인 방향을 제시하는 방식은 앞으로 더 자주 보게 될 장면 같다는 생각이 들었습니다.
온라인에서 일어나는 일(계정, 일정, 메시지, 자료 정리)은 늘 예외와 오류가 생기고, 그때마다 사람이 붙어서 해결하는 방식이 아니라 AI가 먼저 "무슨 문제가 일어난 건지"를 해석하고 복구 방향을 잡는 형태로 점점 자연스럽게 넘어갈지도 모르겠습니다.
